3. Generating a 4D-Communication Tensor from computed communication scores
After inferring communication scores for combinations of ligand-receptor and sender-receiver cell pairs, we can use that information to identify context-dependent CCC patterns across multiple samples simultaneously by generating a 4D-Communication Tensor. LIANA handily outputs these score as a dataframe that is easy to use for building our tensor.
In this tutorial we will show you how to use the dataframe saved from LIANA to generate a 4D-Communication Tensor that could be later used with Tensor-cell2cell.
Initial Setup
Before running this notebook
GPUs can substantially speed-up the downstream decomposition. If you are planning to use a NVIDIA GPU, make sure to have a proper NVIDIA GPU driver (https://www.nvidia.com/Download/index.aspx) as well as the CUDA toolkit (https://developer.nvidia.com/cuda-toolkit) installed.
Then, make sure to create an environment with PyTorch version >= v1.8.1 following these instructions to enable CUDA.
https://pytorch.org/get-started/locally/
Enabling GPU use
If you are using a NVIDIA GPU, after installing PyTorch with CUDA enabled, specify gpu_use = True. Otherwise, gpu_use = False. In R, this must be specified during tensor building.
[1]:
library(reticulate, quietly = TRUE)
gpu_use = TRUE
if (gpu_use){
device <- 'cuda:0'
tensorly <- reticulate::import('tensorly')
tensorly$set_backend('pytorch')
}else{
device <- NULL
}
load the necessary libraries
[2]:
library(liana, quietly = TRUE)
[3]:
data_folder = '../../data/liana-outputs/'
output_folder = '../../data/tc2c-outputs/'
env_name = 'ccc_protocols' # conda environment created with ../../env_setup/setup_env.sh
Load Data
Open the list containing LIANA results for each sample/context. These results contain the communication scores of the combinations of ligand-receptor pairs and sender-receiver pairs.
[4]:
context_df_dict <- readRDS(file.path(data_folder, 'LIANA_by_sample_R.rds'))
Create 4D-Communication Tensor
Specify the order of the samples/contexts
Here, we will specify an order of the samples/contexts given the condition they belong to (HC or Control, M or Moderate COVID-19, S or Severe COVID-19).
[5]:
sorted_samples = sort(names(context_df_dict))
[6]:
sorted_samples
- 'HC1'
- 'HC2'
- 'HC3'
- 'M1'
- 'M2'
- 'M3'
- 'S1'
- 'S2'
- 'S3'
- 'S4'
- 'S5'
- 'S6'
[7]:
head(context_df_dict$HC1)
| source | target | ligand.complex | receptor.complex | magnitude_rank | specificity_rank | magnitude_mean_rank | natmi.prod_weight | sca.LRscore | cellphonedb.lr.mean | specificity_mean_rank | natmi.edge_specificity | connectome.weight_sc | logfc.logfc_comb | cellphonedb.pvalue |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| T | NK | B2M | CD3D | 3.983438e-11 | 0.0134542495 | 1.000000 | 8.059861 | 0.9610254 | 3.410586 | 487.75 | 0.08327606 | 1.3008562 | 0.8719799 | 0 |
| Macrophages | NK | B2M | CD3D | 3.186750e-10 | 0.0135072450 | 2.000000 | 8.059599 | 0.9610248 | 3.410500 | 487.00 | 0.08327335 | 1.3005565 | 0.8832177 | 0 |
| NK | NK | B2M | CD3D | 4.979297e-09 | 0.0181475450 | 3.666667 | 7.614378 | 0.9599465 | 3.264099 | 571.25 | 0.07867324 | 0.7909129 | 0.6978778 | 0 |
| T | NK | B2M | KLRD1 | 1.366319e-08 | 0.0003588748 | 5.666667 | 6.865250 | 0.9579074 | 3.297900 | 211.75 | 0.17129308 | 6.9609202 | 0.8624079 | 0 |
| B | NK | B2M | CD3D | 2.039520e-08 | 0.0192306877 | 5.333333 | 7.518543 | 0.9597023 | 3.232586 | 595.00 | 0.07768305 | 0.6812107 | 0.6910179 | 0 |
| Macrophages | NK | B2M | KLRD1 | 2.039520e-08 | 0.0003588748 | 6.666667 | 6.865027 | 0.9579067 | 3.297814 | 210.75 | 0.17128751 | 6.9606205 | 0.8736456 | 0 |
Generate tensor
To generate the 4D-communication tensor, we will to create matrices with the communication scores for each of the ligand-receptor pairs within the same sample, then generate a 3D tensor for each sample, and finally concatenate them to form the 4D tensor.
Briefly, we use the LIANA dataframe and communication scores to organize them as follows:
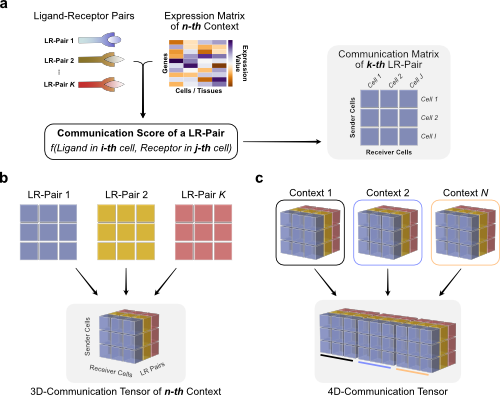
Next we will apply some additional preprocessing (transformations/filtering) to the communication scores. Important parameters include:
non_negativeandnon_negative_fillas Tensor-cell2cell by default expects non-negative values, any values below 0 will be set to 0 (e.g. this is relevant if one wants to use e.g. theLRlog2FCscore function). If you used a pipeline that generated negative scores, we suggest replacing these with 0. Otherwise, by default, Tensor-cell2cell will treat these as NaN. Since we used the magnitude rank score, which is non-negative, these parameters won’t affect our results.invertandinvert_funconvert the communication score before using it to build the tensor. In this case, the ‘magnitude_rank’ score generated by LIANA considers low values as the most important ones, ranging from 0 to 1. In contrast, Tensor-cell2cell requires higher values to be the most important scores, so here we pass a function (function (x) 1 - x) to adapt LIANA’s magnitude-rank scores (subtracts the LIANA’s score from 1). If using other scores coming from one of the methods implemented in LIANA, a similar transformation can be done depending on the parameters and assumptions of the scoring method.outer_fraccontrols the elements to include in the union scenario of thehowoptions. Only elements that are present at least in this fraction of samples/contexts will be included. When this value is 0, the tensor includes all elements across the samples. When this value is 1, it acts as usinghow='inner'.
[8]:
context_df_dict <- liana:::preprocess_scores(context_df_dict = context_df_dict,
outer_frac = 1/3, # Fraction of samples as threshold to include cells and LR pairs.
invert = TRUE, # transform the scores
invert_fun = function(x) 1-x, # Transformation function
non_negative = TRUE, # fills negative values
non_negative_fill = 0 # set negative values to 0
)
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Inverting `magnitude_rank`!
Next, we will transform the structure of the communication scores from a set of 2D-matrices for each sample into a 3D Tensor where the third dimension is sample/context. The key parameters when building a tensor are:
howcontrols which ligand-receptor pairs and cell types to include when building the tensor. This decision depends on whether the missing values across a number of samples for both ligand-receptor interactions and sender-receiver cell pairs are considered to be biologically-relevant. Options are:'inner'is the more strict option since it only considers only cell types and LR pairs that are present in all contexts (intersection).'outer'considers all cell types and LR pairs that are present across contexts (union).'outer_lrs'considers only cell types that are present in all contexts (intersection), while all LR pairs that are present across contexts (union).'outer_cells'considers only LR pairs that are present in all contexts (intersection), while all cell types that are present across contexts (union).
fillindicates what value to assign missing scores whenhowis set to'outer', i.e., those cells or LR pairs that are not present in all contexts. During tensor component analysis, NaN values are masked such that they are not considered by the decomposition objective. This results in behavior of NaNs being imputed as missing values that are potentially communicating, whereas if missing LRs are filled with a value such as 0, they are treated as biological zeroes (i.e., not communicating). For additional details and discussion regarding this parameter, please see the missing indices benchmarking.'lf_fill': value to fill missing (across contexts) LR pairs with'cell_fill': value to fill missing (across contexts OR LR pairs) cell types with
[9]:
tensor <- liana_tensor_c2c(context_df_dict = context_df_dict,
sender_col = "source", # Column name of the sender cells
receiver_col = "target", # Column name of the receiver cells
ligand_col = "ligand.complex", # Column name of the ligands
receptor_col = "receptor.complex", # Column name of the receptors
score_col = 'magnitude_rank', # Column name of the communication scores to use
how='outer', # What to include across all samples
lr_fill = NaN, # What to fill missing LRs with
cell_fill = NaN, # What to fill missing cell types with
lr_sep='^', # How to separate ligand and receptor names to name LR pair
context_order=sorted_samples, # Order to store the contexts in the tensor
sort_elements = TRUE, # Whether sorting alphabetically element names of each tensor dim. Does not apply for context order if context_order is passed.
conda_env = 'ccc_protocols', # used to pass an existing conda env with cell2cell
build_only = TRUE, , # set this to FALSE to combine the downstream rank selection and decomposition steps all here
device = device # Device to use when backend is pytorch.
)
[1] 0
Loading `ccc_protocols` Conda Environment
Building the tensor using magnitude_rank...
Evaluate some tensor properties
Tensor shape
This indicates the number of elements in each tensor dimension: (Contexts, LR pairs, Sender cells, Receiver cells)
[10]:
tensor$shape
torch.Size([12, 1054, 10, 10])
Missing values
This represents the fraction of values that are missing. In this case, missing values are combinations of contexts x LR pairs x Sender cells x Receiver cells that did not have a communication score or were missing in the dataframes.
[11]:
tensor$missing_fraction()
Sparsity
This represents the fraction of values that are a real zero (excluding the missing values)
[12]:
tensor$sparsity_fraction()
Fraction of excluded elements
This represents the fraction of values that are ignored (masked) in the analysis. In this case it coincides with the missing values because we did not generate a new tensor.mask to manually ignore specific values. Instead, it automatically excluded the missing values.
[13]:
tensor$excluded_value_fraction() # Percentage of values in the tensor that are masked/missing
Export Tensor
Here we will save the tensor so we can use it later with other analyses.
[14]:
reticulate::py_save_object(object = tensor,
filename = file.path(output_folder, 'BALF-Tensor-R.pkl'))